
15·
8 days agoI never said I follow the law, I’m just wondering what the law says ;)
old profile: /u/antonim@lemmy.world
I never said I follow the law, I’m just wondering what the law says ;)
Honestly much of your reply is confusing me and doesn’t seem to be relevant to my questions. This is what I think is crucial:
Just because a file is cached on your device does not mean you are the legal owner of that content forever.
What does being “the legal owner forever” actually entail, either with regards to a physical book or its scan? And what does that mean regarding what I can legally do with the cached file on my computer?
Well, there’s the relevant XKCD. Things can be popular/non-niche, yet plenty of people still don’t know about them.
M&B is not a household name, but being ‘niche’ also sounds like much too strong of a word to me. Idk. Czech point-and-click games are niche, traditional roguelikes (NetHack, etc.) are niche… by my metrics, at least.
Is M&B really niche? I’d never call it niche, am I that out of touch?

https://github.com/elementdavv/internet_archive_downloader
This one? I’ll definitely give it a try.
FYI, there are multiple methods to download “digitally loaned” books off IA, the guides exist on reddit. The public domain stuff is safe, but the stuff that is still under copyright yet unavailable by other means (Libgen/Anna’s Archive, or even normal physical copies) should definitely be ripped and uploaded to LG.
The method I use, which results in best images, is to “loan” the book, zoom in to load the highest resolution, and then leaf through the book. Periodically extract the full images from your browser cache (with e.g. MZCacheView). This should probably be automatised, but I’m yet to find a method, other than making e.g. an Autohotkey script. When you have everything downloaded, the images can be easily modified (if the book doesn’t have coloured illustrations IMO it is ideal to convert all images to black-and-white 2-bit PNG), and bundled up into a PDF with a PDF editor (I use X-Change Editor; I also like doing OCR, adding the bookmarks/outline, and adding special page numbering if needed - but that stuff can take a while and just makes the file easier to handle, it’s not necessary). Then the book can be uploaded to proper pirate sites and hopefully live on freely forever. Also there are some other methods you can find online, on reddit, etc.
Produce infinite copies of bread loaves, and then get arrested because the baker lobby doesn’t like that.
So basically you’re the protagonist of this twitter(?) shitpost:

Excuse me, is that linguistic prescriptivism?


Has that ever happened, though? I rarely see Mastodon comments here at all…
That honestly sounds pretty good. But there are no followers on Lemmy, so the mechanism wouldn’t make much sense here.
I’ve just reported you to the mods. It was nice to know you.
As a gay guy, I call bullshit on that, unless you’re bi and have first-hand experience.
This so much. Years ago I’ve had it push Moon landing denial videos in my recommendations, even though I’ve never watched videos on conspiracies or anything of the sort at the time. The closest I got were pop-sci channels such as Vsauce, Numberphile… It’s just trying to hook you onto the garbage content and garbage ideas because they have good and loyal viewership.
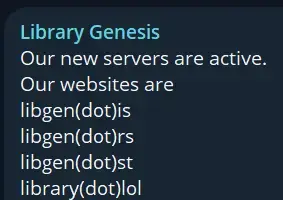
Yes, it’s https://t.me/library_genesis_libgen_bot
Why they were down, you mean? In their TG channel they mentioned a cyberattack, that’s all I know.
True, the .li domain was still fine.
There’s also Anna’s Archive, which I use primarily, since it provides downloads not just from their own db, but links to Libgen and other places where the given book is available.
Most domains (other than .li) were down for several days, making people worried it’s gone for good.
Perhaps a paid app to track and manage your subscriptions…

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
(Sorry for the late response.) Well it depends a lot on the site. Since I focus on books and scholarly articles, the ideal way is to find the URL of the original PDF. The website might show you just individual pages as images, but it might hide the link to the PDF somewhere in the code. Alternatively, you might just obtain all the URLs of the individual page images, put them all into a download manager, and later bundle them all into a new PDF. (When you open the “inspect element” window, you just have to figure out which part of the code is meant to display the pages/images to you.) Sometimes the PDFs and page images can be found in your browser cache, as I mention in the OP. There’s quite some variety among the different sites, but with even the most rudimentary knowledge of web design you should be able to figure out most of them.
If need help with ripping something in particular, DM me and I’ll give it a try.